Experimental methods, created # 2023-08-08 10:57
To understand the experiments in this repository you need to read At a glance, below. To understand why, you need to read Context, which comes after it.
At a glance
!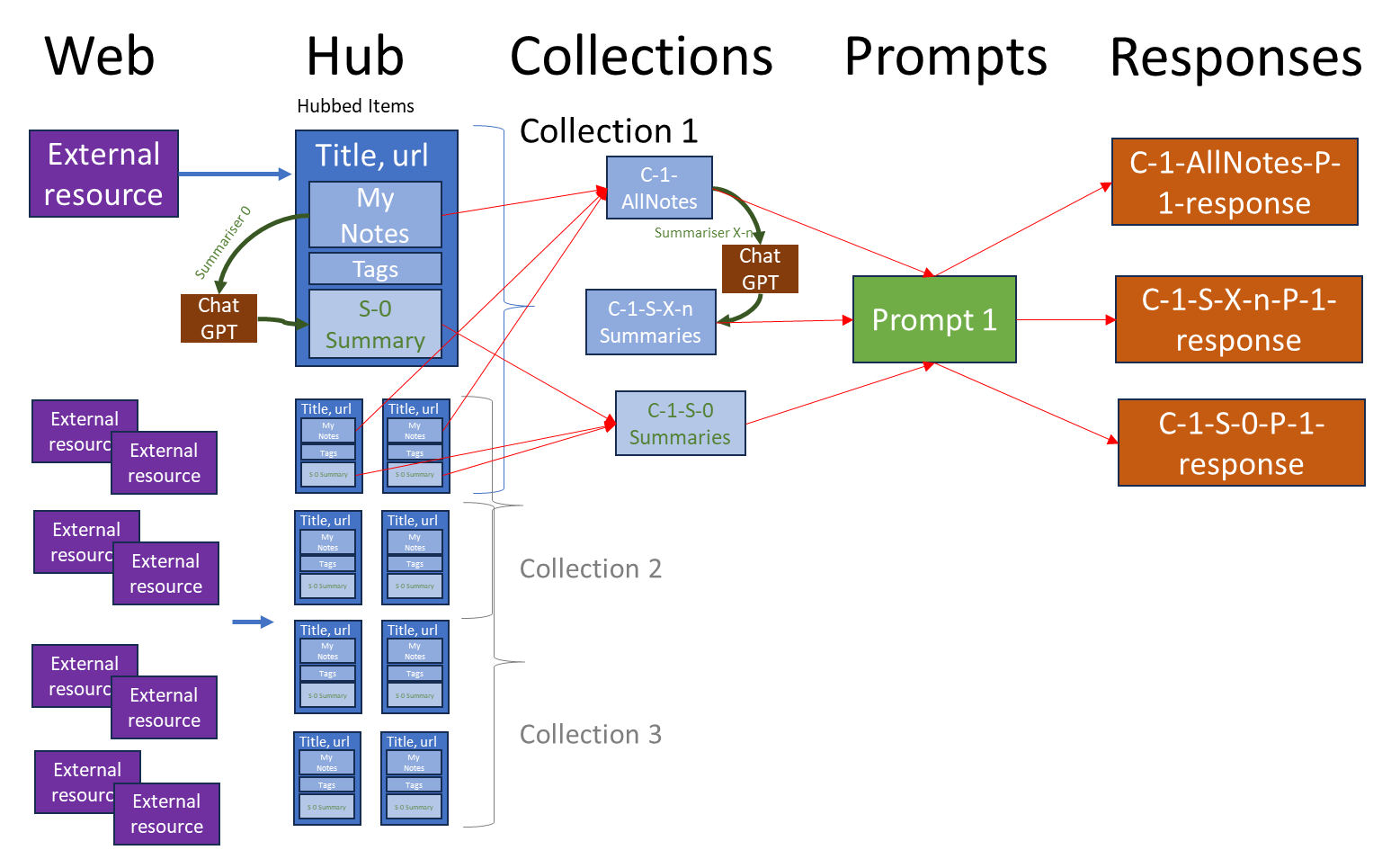
- External resources, left, are content on the web worth Hubbing
- Hubbed items are database records composed of:
- title and URL
- my notes: what I found interesting in the article, and why
- tags (currently manually generated)
- summaries of my notes, generated automatically by ChatGPT using the summariser built into the pilot ChatGPT integration (Summariser 0, or "S-0")
- Summarisers are explained below
- Type (Like, Think or Do): irrelevant to AI for now but pretty important to humans - see All the Stuff you Like, Think and Do in one place
- Hubbed items can be organised into Collections using the MyHub interface.
- The diagram shows Collection 1 ("C-1"), which for example may correspond to all The Best Stuff I Like or Do or Think about Everything tagged ai & disinformation, Anytime
- More generally, Collections are numbered, so each experiment involves a Collection "C-n" (n=1,2,3...).
- For each Collection, experiments can be run using several files:
- Currently I can use the pilot MyHub ChatGPT integration already in place to send the Summariser-0 summaries of Collection 1 ("C-1-S-0") to ChatGPT using any prompt
- The entirety of the Notes in the Collection can also be used to create "C-1-AllNotes", by passing the Collection's RSS feed through the rss to clean notes prompt manually
- C-1-AllNotes are also processed using 2 or more other Summarisers to compare against Summariser-0.
- These Summarisers are called S-n (n=1,2,3...)
- Each S-n can be set to a maximum word length X, as each Summariser needs to be tested at different word lengths
- Each experiment therefore involves a Summariser called "S-n-X" ("Summariser S-n set to max. word length of X") operating on the Collection C-n, resulting in "C-1-S-n-X" being sent to ChatGPT
- What happens next depends on which method I'm using (see LLM integration plans):
- API-based AIgent approach: I take the above three files (C-1-S-0, C-1-AllNotes and C-1-S-n-X) and send them to ChatGPT using a Prompt "P-n" (in the above diagram, Prompt 1, or "P-1").
- Integrating MyHub.ai with GPTs: GPTs require a file upload, so I need to take the above files and manually drag them into the GPT's interface
- Either way, this creates up to three responses to be compared and analysed:
- C-1-S-0-response-P-1
- C-1-AllNotes-response-P-1
- C-1-S-n-x-response-P-1
- The same experiment can be done with a variety of Prompts, Collections and Summarisers, with the Summarisers set to different maximum lengths.
Context
Why such a complicated looking experimental method?
Today's pilot integration
Right now, with pilot MyHub ChatGPT integration, I can use any Prompt I like to interrogate ChatGPT about any Collection of resources, but in all cases I am sending "S-0 summaries" - summaries of the resources generated by "Summariser 0", encoded into MyHub.ai.
However, S-0 generates very short summaries of the notes I wrote about each resource. This is so a maximum number of resources can be sent to ChatGPT at any time, but this happens even when the Collection is actually quite small and I could actually send the entirety of my notes.
This begs some questions - for example, given the same prompt and collection:
- does using the full note improve over using short summary?
- what happens when the full notes are too long, exploding the ChatGPT token limit?
- if I was to use another Summariser to create longer summaries, how does that compare with using the S-0 summaries and the full note?
Then there's the questions of the Prompts. What's the best Prompt to create a newsletter summary? A knowledge visualisation? To generate ideas for a blog post or a paper? And does each prompt work well for all collections, or only some?
In fact, to optimise the LLM integration plans I need to test quite a few moving parts, so each experiment involves a number of different variables:
- the Agent Prompt or the GPT, corresponding to the task the Agent is designed to perform for the User
- the Collection of Hubbed items created by the User, to which the Agent Prompt is applied
- the Summariser used (explained below)
- the maximum length applied using that Summariser (explained below).
One of my first experiments, for example, is called C-1-S-1-150-P-1: testing Prompt 1 on Collection 1 using Summariser 1 set to a max length of 150 words. Let's take each in turn:
The right Prompt for each Agent
When I started investigating this I thought that designing each Agent would just be a question of finding the right Prompt.
For example, Prompt 1 is written to take a Collection of Hubbed notes and:
"write a 500 word editorial summarising the main themes ... in particular highlighting themes common to several articles. Follow the editorial with the articles listed in the following format:
article title
An 80 word summary of the article.
Provide all content in markdown format, with each article title linked to the URL provided with it." - Prompt 1 - newsletter
But if it was that simple, I would have done many experiments by now.
The right Summariser
There's a complicating factor: the ChatGPT token limit.
I'm using the ChatGPT3.5 API, which gives me a 16k context - ie, the content I throw at ChatGPT, and the content it throws back, should not be more than 16000 tokens, or ~12000 words. The moment I break that limit, ChatGPT will start "forgetting" earlier parts of the conversation.
After analysing the most active Hubs, I calculated that if MyHub Agents sent the full notes of each Hubbed item, it would break the token limit for any Collection over 15-20 items.
So we need a Summariser: once an Editor has Hubbed an item, MyHub checks its length. If it is over a certain length ("Summary Threshold"), MyHub will ask ChatGPT to create a Summary of the note, of length Summary Threshold.
Moreover, we also need Collection Composer: when an Editor activates an Agent, this algorithm checks the total length of all the notes in the Collection:
- if it's under (say) 8000 tokens, then ChatGPT is sent the full notes.
- on the other hand, if all the notes' Summaries total 8000 tokens, the Collection is rejected as too large from the outset
- something interesting happens in the middle ground: where the notes total over 8000 tokens, Collection Composer substitutes some notes with their Summaries, starting with notes which are not Highlighted and which are only slightly over the Summary Threshold.
In this way ChatGPT gets the Editor's notes of the Collection where possible, and their Summaries if the Collection's notes are either too numerous, too long, or both. The actual algorithm is spelt out a little more explicitly in LLM integration plans, while all Summarisers can be found in summarisers in summary.
Questions to answer
So we now have several questions requiring experiments to answer:
- What is the best Agent Prompt for each task?
- What is the best Summariser Prompt for capturing the essence of each note?
- How long should Summary Threshold be?
- How do these considerations change when I use a GPT instead?
Moreover, is the best combination of Summariser Prompt, Summary Threshold and (Agent Prompt or GPT) good for all Collections, or just the one I used in my first round of tests? So I need to test all these variables against multiple Collections.
Hence the name of my first experiment (C-1-S-1-150-P-1): testing Prompt 1 on Collection 1 using Summariser 1 set to a max length of 150 words. These files, the resulting responses from ChatGPT and my analyses of them can all be found in experiment log.
archived content
experimental nomenclature - archived experiment round 1 - archived